|
COCA 20k / 60k lemmas list (compare
to COCA 100k word forms list) There are a number of different formats available for the
20,000-60,000 word list, as shown below. Click here to
order.
|
1. Wordlist |
-
Lemma, rank, part of speech, dispersion score
-
Text or Excel file: can be
printed / copied
-
List sizes:
5,000, 20,000, 60,000
|
Short sample (see
expanded sample: 6,000 entries: every tenth word 1-60,000)
|
rank |
lemma / word |
PoS |
frequency |
dispersion |
|
7309 |
attic |
n |
2711 |
0.91 |
|
17311 |
tearful |
j |
542 |
0.93 |
|
27303 |
tailgate |
v |
198 |
0.85 |
|
37310 |
hydraulically |
r |
78 |
0.83 |
|
47309 |
unsparing |
j |
35 |
0.83 |
|
57309 |
embryogenesis |
n |
22 |
0.66 |
|
2. Wordlist + genre frequency |
-
Overall frequency (+dispersion), as above. But also
includes:
-
Frequency in
five main genres: spoken, fiction, popular magazine,
newspaper, academic
-
Frequency in each of the 40+ sub-genres (e.g. MAG-Sports,
NEWS-Financial, ACAD-Medicine)
-
With the frequency data for specific genres and
sub-genres, you can create customized wordlists for
specific purposes: medical, technology, sports, etc.
-
Excel file; can be
printed / copied
-
List sizes: 5,000, 20,000, 60,000
|
Short sample (see
expanded sample: 6,000 entries: every tenth word 1-60,000)
Note 1: Due to space constraints, in this sample only six of the 40+
sub-genres are shown (M1: MAG-Financial; M2: MAG-Science/Tech; N1:
NEWS-Sports; N2: NEWS-Editorial; A1: ACAD-Law/PolSci; A2: ACAD-Medicine).
Note 2: The green shading for the five main genres highlights those
words whose frequency in that genre are at least double what would
otherwise be expected (based on genre size).
|
rank |
lemma / word |
PoS |
disp |
totFreq |
spok |
fic |
mag |
news |
acad |
M1 |
M2 |
N1 |
N2 |
A1 |
A2 |
|
25083 |
piglet |
n |
0.88 |
239 |
20 |
97 |
54 |
46 |
22 |
10 |
2 |
3 |
3 |
0 |
2 |
|
25088 |
woodsman |
n |
0.70 |
300 |
10 |
176 |
77 |
12 |
25 |
1 |
2 |
1 |
3 |
2 |
0 |
|
25090 |
candied |
j |
0.87 |
242 |
17 |
49 |
102 |
73 |
1 |
0 |
1 |
2 |
1 |
0 |
0 |
|
25093 |
metacognitive |
j |
0.69 |
306 |
0 |
0 |
0 |
0 |
306 |
0 |
0 |
0 |
0 |
0 |
0 |
|
25107 |
industry-wide |
j |
0.89 |
236 |
16 |
2 |
64 |
109 |
45 |
19 |
10 |
2 |
1 |
10 |
6 |
|
25108 |
health-food |
j |
0.85 |
246 |
10 |
19 |
154 |
55 |
8 |
6 |
4 |
7 |
1 |
0 |
2 |
|
25110 |
posterior |
n |
0.88 |
240 |
6 |
30 |
36 |
27 |
139 |
0 |
5 |
4 |
0 |
0 |
99 |
|
3. Wordlist + collocates
(see
www.collocates.info
for full info) |
-
More than
4,800,000 entries, showing which words occur most
frequently with others.
-
200-300
collocates each for most of the top 20,000-30,000 words,
and somewhat fewer for less-common words.
-
Collocates provide useful information on word
meaning and usage
-
List sizes:
5,000, 20,000, 60,000
|
Short sample (see
expanded sample: 45,390 entries; every hundredth word 1-60,000):
|
nodeID |
node |
nodePoS |
collocate |
collPoS |
freq |
MutInfo |
preNode |
postNode |
% preNode |
| 15349 |
smolder |
v |
still |
r |
76 |
4.39 |
74 |
2 |
0.97 |
| 15349 |
smolder |
v |
fire |
n |
59 |
6.33 |
39 |
20 |
0.66 |
| 15349 |
smolder |
v |
eye |
n |
43 |
4.41 |
24 |
19 |
0.55 |
| 15349 |
smolder |
v |
cigarette |
n |
26 |
6.93 |
17 |
9 |
0.65 |
| 15349 |
smolder |
v |
ash |
n |
15 |
7.42 |
5 |
10 |
0.33 |
| 15349 |
smolder |
v |
ember |
n |
14 |
10.62 |
4 |
10 |
0.28 |
| 15349 |
smolder |
v |
resentment |
n |
14 |
8.26 |
2 |
12 |
0.14 |
|
4. N-grams
(see
www.ngrams.info
for full info) |
-
Format #1: All n-grams that occur three times or more:
6.2 million 2-grams, 11.9 million 3-grams, 8.3 million
4-grams, 3.4 million 5-grams. Available +/- case
sensitive, +/- with part of speech
-
Format #2: All distinct 2-5 grams in the corpus.
(Hundreds of millions of rows of data.) N-grams table linked to "lexicon" table.
With this data, you can run an unlimited number of queries against the
corpus from your own machine
|
Short sample (see
expanded sample: 194,000 n-grams)
Note: for ease of presentation, the words themselves are displayed
in this sample table, as in format #1 above. You can also see the
part of speech for each word in the string. In format #2 above, there are two
tables: a lexicon (with a unique wordID, along with word form,
lemma, and PoS), and an n-grams table that has the wordID values
from the lexicon table (as integer values, for smaller size and
faster searching).
|
frequency |
word1 |
word2 |
word3 |
|
1419 |
much |
the |
same |
|
461 |
much |
more |
likely |
|
432 |
much |
better |
than |
|
266 |
much |
more |
difficult |
|
235 |
much |
of |
the |
|
226 |
much |
more |
than |
|
195 |
much |
less |
a |
|
194 |
much |
like |
a |
|
5. eBook |
-
Top 20-30
collocates for each word, grouped by part of speech, as well
as synonyms (for most words)
-
Note that this file cannot be edited or printed or
copied from
-
List sizes: 5,000, 10,000, 20,000
|
Short sample (see
expanded sample: 2,700 entries; every seventh word 1-20,000):
1421 blow
v
noun wind•, whistle, air, •nose,
•smoke, breeze•, •face,
hair, •kiss, head, window, horn, •candle,
•mind,
storm•
misc •away, •through,
•across
out •candle, window, •breath,
air, wind•, •smoke, •knee,
tire, •match up •building, plot•,
bomb, plane, car, bridge, wind•, threaten•
off •steam, head•, roof•,
leg•
● whoosh, gust, waft, puff || move, propel, drive,
carry
27254 | 0.94 F |
19964 bodice
n
adj black, tight, white, embroidered, fitted,
red, blue, gathered, beaded, pleated noun dress,
skirt, gown, lace, sleeve, •ripper, back, satin,
silk, waist verb embroider, rip, pull,
•fit, feature•, wear, cover, lace, cut,
tuck•
421 | 0.86 F |
|
6. Printed book
(available online, e.g.
Routledge or
Amazon) |
-
Top 20-30
collocates for each word, grouped by part of speech.
-
Also contains 31 frequency-based, thematically-oriented
lists
-
List size: 5,000 words
|
Short sample (see
expanded sample: every seventh page in the book):
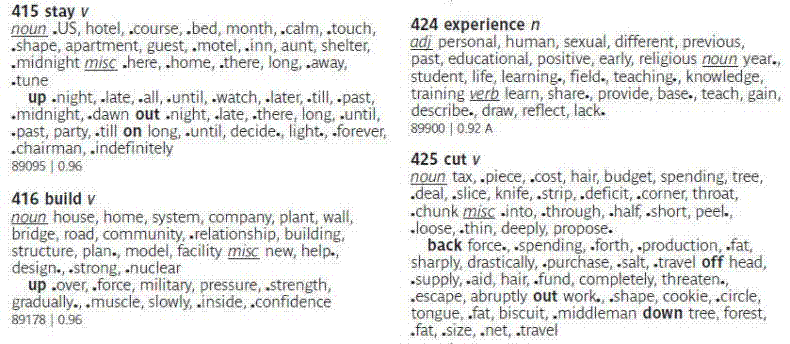
|
